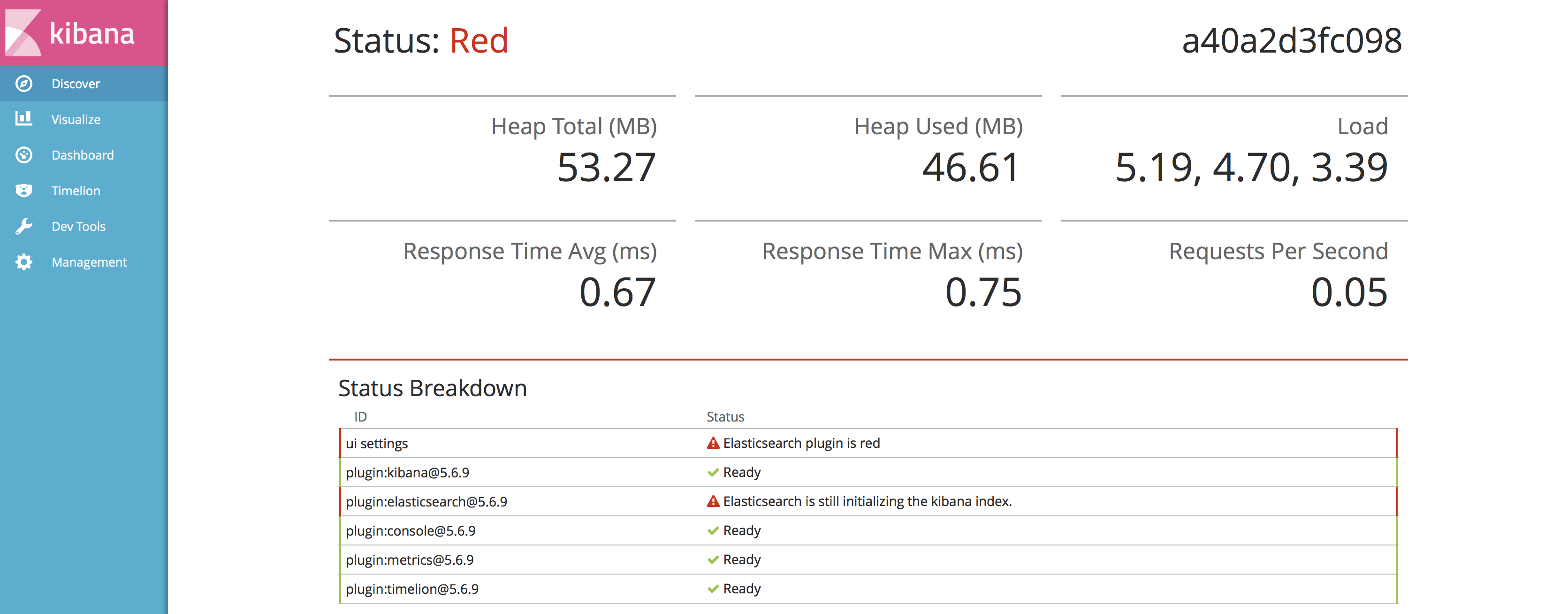
Gestern habe ich ohne lange zu Überlegen Kibana auf meinem ELK-Server gelüpft. Schlechte Idee:
{"type":"log","@timestamp":"2021-02-11T23:20:13+01:00","tags":["error","savedobjects-service"],"pid":501,"message":"This version of Kibana (v7.11.0) is incompatible with the following Elasticsearch nodes in your cluster: v7.10.0 @ 10.1.2.3:9200 (10.1.2.3)"}
Abbruch, zurückbuchstabieren — aber wie?
Zuerst überprüft man, was die letzte funktionierende vorherige Version war:
$ apt-cache madison kibana
kibana | 7.11.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.10.2 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.10.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.10.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.9.3 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.9.2 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.9.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.9.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.8.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.8.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.7.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.7.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.6.2 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.6.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.6.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.5.2 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.5.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.5.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.4.2 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.4.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.4.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.3.2 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.3.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.3.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.2.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.2.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.1.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.1.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.0.1 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
kibana | 7.0.0 | https://artifacts.elastic.co/packages/7.x/apt stable/main amd64 Packages
Somit muss ich versuchen, 7.10.2 über 7.11.0 zu installieren. Doch wie macht man das?
# apt-get install kibana=7.10.2
Und damit beim nächsten Lauf Kibana 7.11.0 nicht erneut installiert wird, benötigt man noch einen Eintrag in /etc/apt/preferences:
... Package: kibana Pin: version 7.10.2 Pin-Priority: 1001