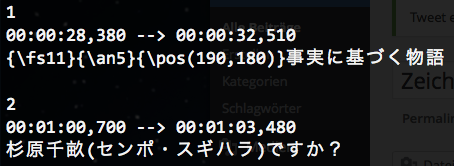
Heute bin ich einer .srt Untertitel-Datei eines Films aus Asien über den Weg gelaufen, welche in VLC nur Zeichensalat anzeigte:
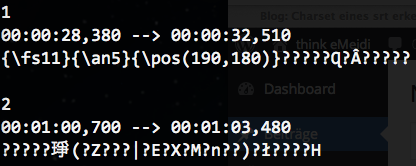
Ziel war es, diese Untertitel-Datei mit iconv in UTF-8 zu konvertieren. Doch bevor ich damit beginnen konnte, musste ich herausfinden, wie der Ursprungszeichensatz hiess.
Glücklicherweise existiert genau für solche Fragestellungen ein Python-Modul, welches einem das Rätselraten abnimmt. Das Modul heisst chardet, welches ich kurzerhand mittels MacPorts installierte:
# port install py27-chardet
Auf Grund einer Unterlassung früherer Tage musste ich einmalig noch das Python auswählen, welches auf der Kommandozeile standardmässig ausgeführt wird:
# port select --set python python27
Via: ImportError: No module named gnuradio
Anschliessend konnte ich die Untertitel von Python parsen lassen:
$ python -c 'import chardet,sys; print chardet.detect(sys.stdin.read())' < Sugihara\ Chiune.srt
{'confidence': 0.99, 'encoding': 'SHIFT_JIS'}
Via: How to auto detect text file encoding?
Bewaffnet mit dieser Information konnte ich nun iconv zu Hilfe ziehen:
$ iconv -f SHIFT-JIS -t UTF-8 Sugihara\ Chiune.srt > Sugihara\ Chiune.UTF-8.srt
Quelle: Japanese Encoding Conversion
Das Resultat sah nun so aus: