CLD ist der Compact Language Detector welcher in Google-Projekten zum Einsatz kommt — primär einmal in Googles Web-Browser Google Chrome. Mit diesem Detektor ist es möglich, die Sprache eines Textes zu erkennen.
Der Code des Detektors ist quelloffen, weshalb findige Entwickler den Code aus dem Google-Projekt herausgelöst haben und als eigenständige Linux-Library bereitstellen:
CLD – Compact Language Detector
Ich habe diesen Detektor in ein Projekt integriert und dabei die PHP-basierte Lösung Package Information: Text_LanguageDetect abgelöst, weil ich dessen Erkennungsgenauigkeit nicht als herausragend empfunden habe.
Download und Kompilation der Library
Zuerst klonte ich den Quellcode auf das Entwicklungssystem:
$ cd /tmp $ git clone https://github.com/mzsanford/cld.git
Anschliessend versuchte ich die Kompilierung und Installation, doch dies schlug fehl:
$ cd /tmp/cld $ ./configure configure: error: cannot find install-sh or install.sh in "." "./.." "./../.."
Zuerst musste ich mir folgende Ubuntu/Debian-Pakete herunterladen:
# apt-get install build-essential libtool autoconf automake pkg-config
Via: run autoreconf -f -i -Wall,no-obsolete to fix install-sh problem
Anschliessend musste ich die Kompilierungsinformationen des Projektes neu generieren:
$ cd /tmp/cld $ autoreconf -f -i -Wall,no-obsolete
Nach diesem Schritt klappte es auch mit der Kompiliererei:
$ cd /tmp/cld $ ./configure
Installation der Library
Nun musste die Library noch installiert werden, was mit folgendem Befehl erfolgte:
# cd /tmp/cld # make install
Installation der Python-Bindings
Noch war ich nicht am Ziel. Nachdem die Shared Library installiert war, fehlten noch die Python-Bindings, mit welchen die Library mittels eines simplen import cld in ein Python-Script importiert werden kann:
# cd /tmp/cld/ports/python # make install ... pycldmodule.cc:5:20: Schwerwiegender Fehler: Python.h: Datei oder Verzeichnis nicht gefunden Kompilierung beendet.
Sorry, aber den Laptop habe nicht ich aufgesetzt — Linux läuft bei mir immer unter der englischen Sprache …
Es fehlte der Python-Quellcode, welchen ich folgendermassen nachrüstete:
# apt-get install python-dev
Anschliessend funktionierte auch der folgende Befehl sauber:
# cd /tmp/cld/ports/python # make install
Die Originalversion dieses Artikels liess das Paket pkg-config nicht installieren. Ist dieses Paket nicht vorhanden, erscheint bei der Kompilierung folgende Fehlermeldung:
/tmp/cld/ports/python# make python -u setup.py build Traceback (most recent call last): File "setup.py", line 12, in**pkgconfig('cld')) TypeError: __init__() keywords must be strings make: *** [build] Error 1
Nachdem pkg-config nachinstalliert wird, klappt es mit der Installation der Python-Bindings problemlos.
Via: Error when installing python bindings
Integration in Python-Scripts
Leider funktionierte die Integration der Library in ein Python-Script mittels import cld nicht:
Traceback (most recent call last): File "", line 1, in ImportError: libcld.so.0: cannot open shared object file: No such file or directory
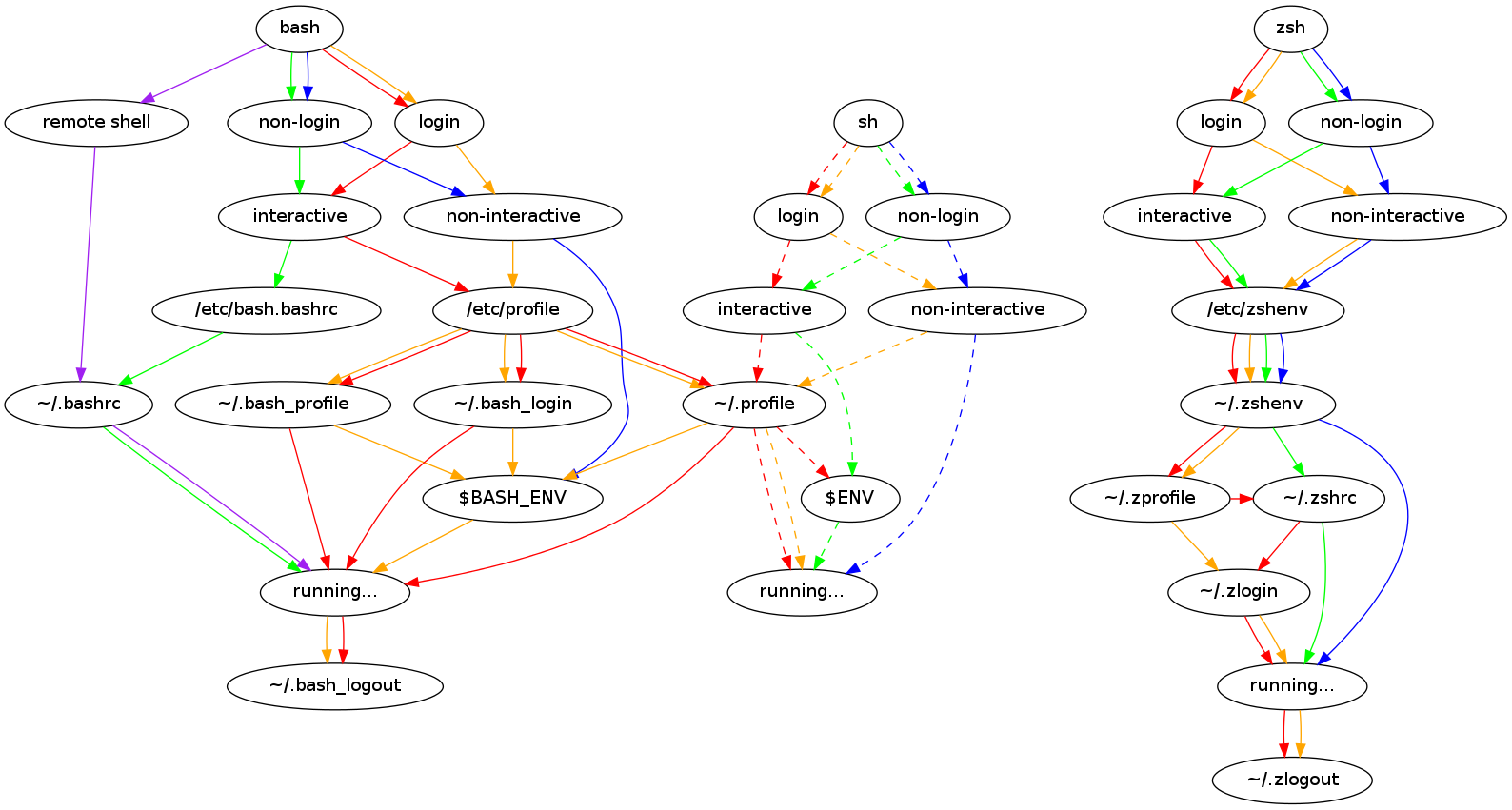
Zuerst musste noch die Shell-Variable LD_LIBRARY_PATH mit dem Pfad auf cld angepasst werden (sowohl in .bashrc als auch in .profile, weil ich immer noch nicht begriffen habe, welche Datei bei einem Shell-Login geladen wird — ich sollte wohl mal Shell startup scripts lesen, doch diese Grafik sagt wohl schon alles zum Thema aus):
... export LD_LIBRARY_PATH="/usr/local/lib:/usr/local/lib/cld"
Via: Language detection with Google’s Compact Language Detector
Alternativ kann das Verzeichnis über die Verzeichnisstruktur /etc/ld.so.conf.d auch systemweit gesetzt werden (Via: How to define LD_LIBRARY_PATH for all applications).
Anschliessend konnte ich mit wenigen Zeilen Python-Code die Spracherkennung für Texte aktivieren:
import cld ... detectedLangName, detectedLangCode, isReliable, textBytesFound, details = cld.detect(plaintext, pickSummaryLanguage=False, removeWeakMatches=False)

{kind=link}