In meinem Netzwerk läuft eine ElasticSearch-, Lucene- und Kibana- oder kurz ELK-Komponente, an welche alle Geräte im Netzwerk per syslog ihre Log-Events zusenden. Gelegentlich muss ich den ELK-Docker-Container herunter- und wieder hochfahren. Da ich ELK auf einem Laptop laufen lassen und die CPU-Frequenz des Geräts auf den tiefstmöglichen Wert für diese CPU festgelegt habe (1200 MHz; Überhitzung führte vorher zu unregelmässigen Abstürzen), kann es manchmal eine Weile dauern, bis ELK nach einem solchen Neustart wieder hochkommt. Doch bis es soweit ist, strahlt einem dieses Kibana Status-Fenster entgegen:
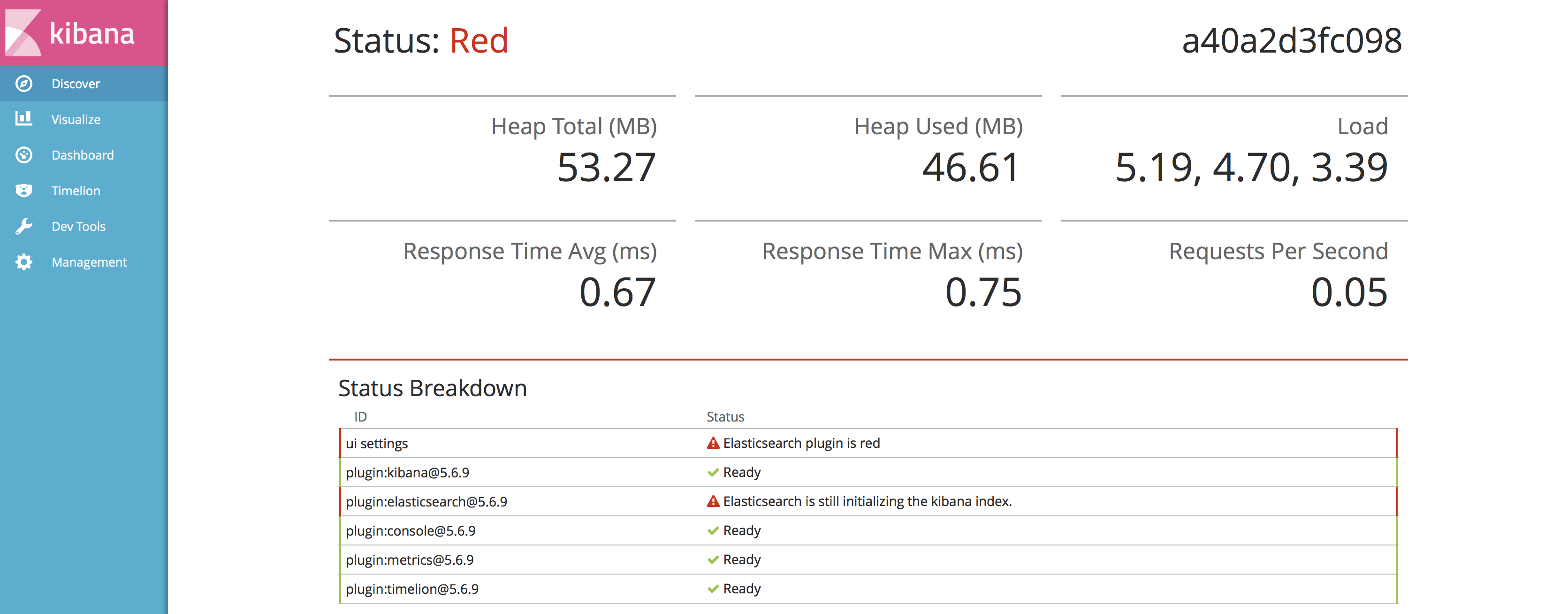
Wenn man sich dafür interessiert, wie weit der Kibana-Index bereits wiederhergestellt ist, ruft folgende URL auf:
http://1.2.3.4:9200/_cluster/health?pretty=true
Im Browser sieht man dort dann nützliche Informationen über den Cluster, und für unseren Fall ganz wichtig, das Attribut active_shards_percent_as_number:
{
"cluster_name" : "elasticsearch",
"status" : "red",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 1753,
"active_shards" : 1753,
"relocating_shards" : 0,
"initializing_shards" : 4,
"unassigned_shards" : 4035,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 10,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 807617,
"active_shards_percent_as_number" : 30.265883977900554
}
Im Browser kann man nun regelmässig diese Seite neu laden und sollte sehen, wie active_shards_percent_as_number kontinuierlich nach oben zählt. Sobald 100 Prozent erreicht sind, läuft der Cluster wieder wie erwartet.
Wer nur eine Kommandozeile zur Verfügung hat, hilft sich folgendermassen:
$ watch -n 1 curl -XGET 'http://1.2.3.4:9200/_cluster/health?pretty=true'
Quelle: Monitor ElasticSearch cluster health – Useful for keeping an eye on ES when rebalancing takes place
