Donnerstag, 14. Februar 2013
Beruflich setze ich mich derzeit mit der Analyse von Inhalten von Web-Sites auseinander. Nachfolgend habe ich einige Erfahrungen aufgelistet, welche ich dabei gemacht habe.
Wir verarbeiten in diesem Projekt Web-Sites, welche wir mit entsprechenden Tools aus dem Web auf den lokalen Rechner gespiegelt haben. Die Web-Site Assets liegen im Dateisystem. Zur Weiterverarbeitung der Daten wurden die HTML-, JS-, CSS- und XML-Rohdaten in eine MySQL-Tabelle gespitzt (12GB) und anschliessend mit Meta-Daten ergänzt.
Ich persönlich bin nicht sicher, ob die Ablage von HTML-Code in der Datenbank die sinnvollste und performanteste Lösung ist, aber dies war nunmal der Stand des Projektes als ich dazu gestossen bin — und daran liess sich nichts mehr rütteln.
Da wir unter anderem auch Volltextsuchen auf die Grunddaten anwenden, hätte ich mir Apache Solr genauer angeschaut und darauf mittels PHP und JSON zugegriffen.
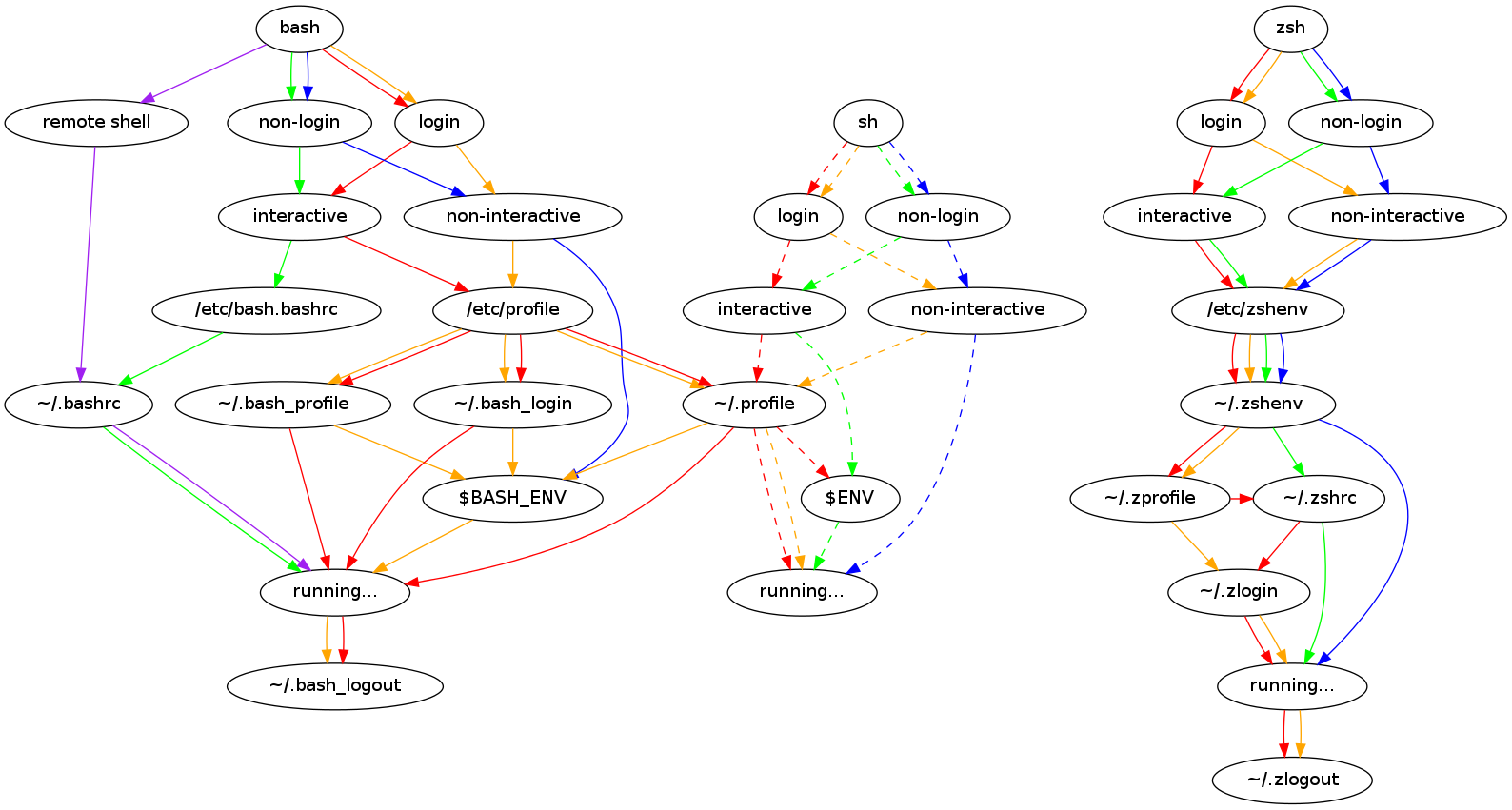
Kommandozeile
Da der Ubuntu-Server aus mir unerfindlichen Gründen mit LAMPP aufgesetzt wurde, befinden sich die Binaries wie php nicht in den Standardpfaden und werden von bash ohne absolute Pfadangabe nicht gefunden. Da man den Interpreter täglich dutzende, wenn nicht gar hunderte Male aufruft, ist es ratsam, das Verzeichnis sofort in die $PATH-Variable des Shells aufzunehmen.
Hier findet man sich in der Shell Startup File Hell wieder. Je nachdem, ob man lokal arbeitet oder sich per SSH einloggt muss der Befehl an einem anderen Ort stehen. Schlussendlich habe ich die nachfolgende Zeile …
...
PATH="$PATH:/opt/lampp/bin"
… ans Ende folgender zwei Dateien angefügt:
Datenbank (MySQL)
Cache aktivieren
Wir führen PHP-Scripts über die Linux-Shell aus. Gerade bei der Entwicklung neuer Scripts sind verschiedene Anläufe nötig, bis alle Bugs und nicht beabsichtigten Funktionen ausgemerzt sind. Da wir oftmals an einem Datenset von 60’000+ Seiten arbeiten, ist es unabdingbar, dass wir eine Cacheing-Lösung anwenden, um Datenbankabfragen im Kurzspeicher zwischenzulagern.
Folgende Parameter in my.cnf aktivieren den in MySQL vorhandenen Cache:
...
[mysqld]
...
query_cache_type = 1
query_cache_size = 512M
query_cache_limit = 32M
Der Geschwindigkeitsgewinn ist immens — nachdem ein Script mit SELECT-Statements zum ersten Mal ausgeführt wurde und dafür mehrere Minuten benötigte, rauscht es in den folgenden Malen innert Sekunden durch.
Programmierung (PHP und Python)
Helper-Funktionen und -Klassen
Wie aus der Web-Entwicklung gewohnt sollte man bei jedem der mit der Zeit entstehenden Scripts zu Beginn Klassen, allgemeine Einstellungen und Funktionen einbinden.
In der Funktionsbibliothek setze ich beispielsweise folgende wichtigen Parameter in globaler Form:
...
error_reporting(E_ALL);
date_default_timezone_set('Europe/Zurich');
Auch die Datenbankverbindung wird mittels meiner MySQL-Klasse hier erstellt und an alle Scripts weitergegeben, welche die Library einbinden.
Aufbau der Scripts
Als ich zum Projekt stiess herrschten Spaghetti-Code in teils monolithischen Scripts vor. Ich habe meine eigenen Scripts dann aber so entwickelt, dass sie dem Unix-Gedanken folgend normalerweise nur eine bestimmte Funktion ausführen, diese dafür aber ausgezeichnet und in sich abgeschlossen. So steht im Normalfall in jedem Script, welches Daten manipuliert, zuoberst ein SQL-Query, welches die zu verändernden Datenbankdaten auswählt.
Bei der Entwicklung wählt man hierbei ein Query, das einen oder nur wenige Werte aus der Datenbank ausliest und verarbeitet — in dieser Phase hat man keine Zeit, möglicherweise fehlerhafte Manipulationen an 60’000+ Seiten durchzuführen.
HTML mit regulären Ausdrücken parsen?
Nein, besonders nicht dann, wenn man konkret an Eigenschaften des SGML-Markup interessiert ist (bspw. Wohin zeigen Links?). Hierzu verwendet man die in PHP standardmässig enthaltene DOMDocument-Bibliothek.
Wichtig ist, dass man bei der Verwendung von E_ALL die loadHTML()-Funktion mittels @ stummschaltet, weil sonst das Terminal mit Warnungen über fehlerhaften HTML-Code (leider an der Tagesordnung) vollgespamt wird:
...
$dom = new DOMDocument();
@$dom->loadHTML($html);
$elements = $dom->getElementsByTagName('a');
HTML manipulieren — und Fallstricke
Für jede HTML-Seite erstellen wir eine Nur-Text-Version. Hierzu verwenden wir html2text.py von Aaron Swartz selig. Bevor das HTML aber umgewandelt wird, säubern wir die HTML-Datei auf eigene Faust. Auch hier kommt DOMDocument zum Zug.
Wir suchen dabei zuerst einmal Elemente jeglicher Art, deren ID oder Klasse den String nav, menu und breadcrumb enthält. Die Navigation interessiert uns nämlich nicht, und noch schlimmer: Sie verfälscht teilweise die Resultate, weil in der Navigation gesuchte Begriffe vorkommen.
Hierzu lade ich den HTML-Code wieder in eine DOMDocument und iteriere danach über alle Elemente auf der Suche nach den besagten IDs und Klassennamen:
function cleanNavMenuElements($html = null) {
$dom = new DOMDocument();
@$dom->loadHTML($html);
$changesMade = false;
$elements = $dom->getElementsByTagName('*');
foreach($elements as $element) {
if(preg_match('/^(html|body)$/',$element->nodeName)) {
// Otherwise we might delete the whole DOM!
continue;
}
if($element->hasAttribute('class') && preg_match('/(nav|menu|breadcrumb)/i',$element->getAttribute('class')) > 0) {
status('Found element with class ' . $element->getAttribute('class'));
$element->parentNode->removeChild($element);
$changesMade = true;
// Don't go further if we removed this node already
continue;
}
if($element->hasAttribute('id') && preg_match('/(nav|menu|breadcrumb)/i',$element->getAttribute('id')) > 0) {
status('Found element with id ' . $element->getAttribute('id'));
$element->parentNode->removeChild($element);
$changesMade = true;
}
}
if(!$changesMade) {
return $html;
}
return $dom->saveHTML();
}
Ein Problem manifestiert sich bei der Manipulation aber: Jegliche Anpassungen erfolgen live, was verwirrende Folgen für Schleifen haben kann.
Da die Suche nach obigen ID- und Klassennamen nicht alle Navigationselemente eliminiert, suche ich in einem zweiten Anlauf Tabellen und Listen, deren Elemente ausschliesslich Links enthalten. Dies ist ein guter Indikator, ein Navigationsblock gefunden zu haben.
Hier ist das Problem des sich bei jeder Iteration veränderndem DOM aber sehr ausgeprägt. Wenn ich deshalb durch td-Elemente und li-Elemente iteriere, verwende ich nicht foreach() sondern eine for()-Schleife, deren Counter $i ich immer dann zurücksetze, wenn ich ein Element entferne. Ansonsten wird aus Erfahrung in der Folge eines (oder mehrere Elemente) übersprungen. Damit dies klappt, arbeite ich den DOM Tabellen- respektive Listenweise ab:
$containers = $dom->getElementsByTagName($containerTag);
foreach($containers as $container) {
$items = $container->getElementsByTagName($itemTag);
for($i = 0; $i < $items->length; $i++) {
$item = $items->item($i);
if($item === null) {
continue;
}
$otherTagsPresent = false;
foreach($item->childNodes as $child) {
$tag = $child->nodeName;
if($tag == '#text') {
$text = trim($child->nodeValue);
$len = strlen($text);
if($len < 1) {
//#text is empty, thus not relevant
continue;
}
}
if($tag != 'a') {
$otherTagsPresent = true;
continue;
}
}
if(!$otherTagsPresent) {
$item->parentNode->removeChild($item);
$i = $i-1;
}
}
Weiterverarbeitung der Daten durch Nicht-IT-Profis
Zur Weiterverarbeitung der Auswertungen durch andere, in IT nicht versierte Mitarbeiter habe ich eine Funktion geschrieben, welche eine Pfadangabe sowie CSV-Daten als Argumente übertragen erhält. Die Datei wird geschrieben und gleich anschliessend mittels eines kleinen Python-Scripts (Stichwort: openpyxl) in das bei uns hauptsächlich verwendete XLSX-Format konvertiert.

{kind=link}