Heute durfte ich für einen Kollegen in den USA eine im Internet als Stream verfügbare M6 News-Sendung rippen.
Geoblocker
Damit ich an die m3u8-Datei des Streams herankam, musste ich aber zuerst die Geo-Sperre umgehen. Die Web-Site frägt nämlich beim Aufruf (gleich zweimal) ab, in welchem Land sich der Surfer befindet. Hierzu ruft der JavaScript-Code der Web-Site folgende zwei URLs auf:
Als Antwort erhält der Browser folgenden JSON-Code zurück (IP anonymisiert):
{"offset":"2","isp":"Andreas Fink","areas":[10],"country_code":"CH","asn":"AS6775","ip":"85.195.0.0"}
Diese Antwort bewegt den Player dazu, folgende Fehlermeldung anzuzeigen:
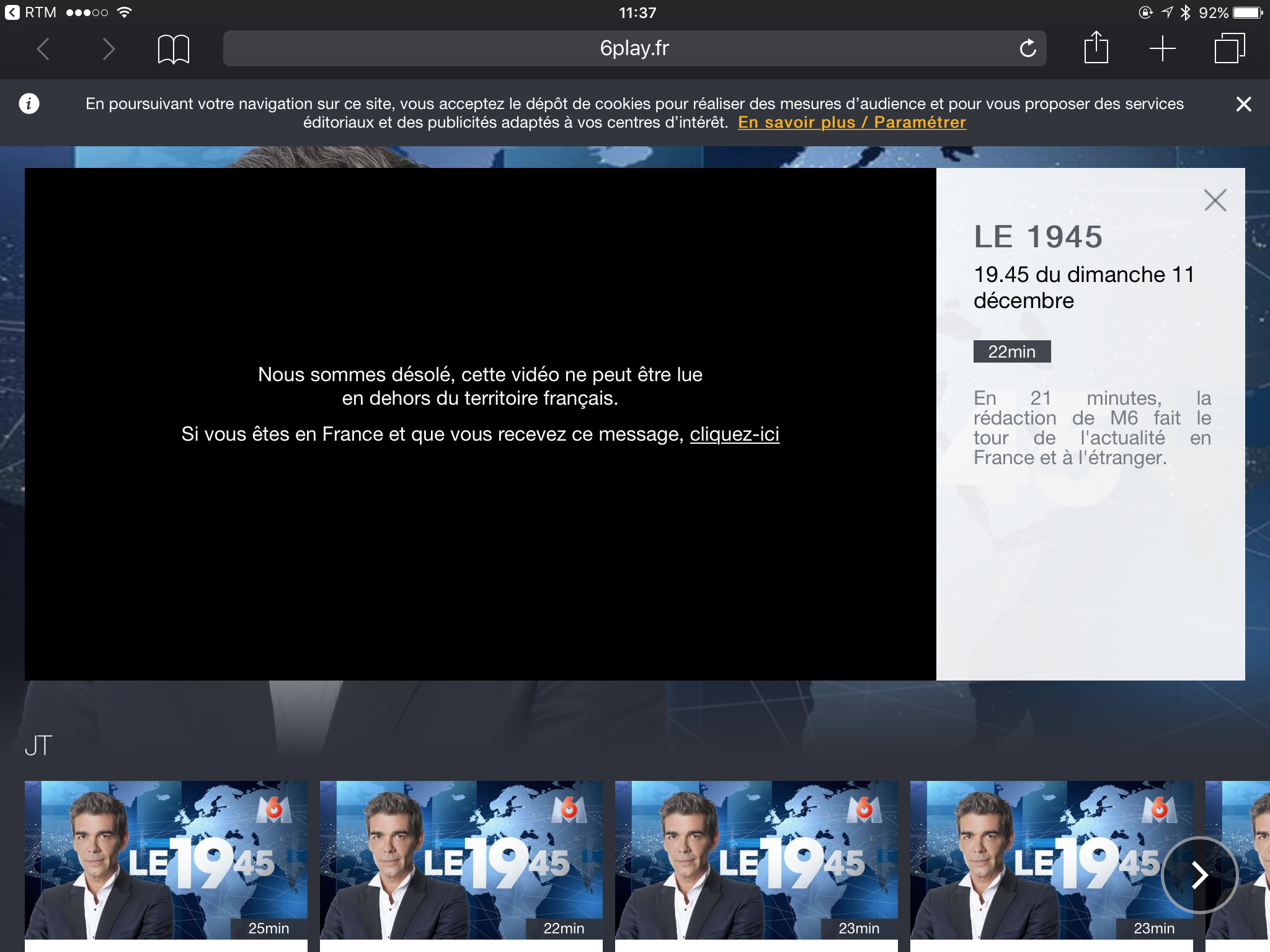
mitmproxy installieren und konfigurieren
Der erste Task war somit klar: Ich musste mit dem quelloffenen Tool mitmproxy alle HTTP(S)-Requests meines iPads proxyifizieren und dann obige JSON-Antwort mit einer validen Antwort ersetzen, so wie sie über einen französischen ISP erfolgen würde.
mitmproxy hatte ich bereits auf meinem lokalen Linux-Server konfiguriert, weshalb ich auf dem iPad in den Netzwerkeinstellungen den Proxy nur noch erfassen musste: 10.0.X.Y:8888.
Auf dem Linux-Server startete ich mitmproxy folgendermassen:
# mitmproxy -p 8888
Als nächstes musste ich noch das mitmproxy-Zertifikat auf dem iPad installieren, damit HTTPS-Verbindungen entschlüsselt und umgeschrieben werden können. Hierzu reicht es, auf dem iPad die folgende URL aufzurufen …
… und den Anweisungen zu folgen (ACHTUNG: Sicherheitssensitive Personen löschen das Zertifikat nach der Verwendung wieder vom iPad. Es findet sich unter Settings > General > Profiles).
Inline-Script zum Umschreiben von Antworten
Damit ich vom Proxy-Server empfangene Antworten der M6-Server umschreiben konnte, musste ich nun noch ein mitmproxy Inline-Script einbauen, welches Aufrufe auf die oben genannten URLs abfängt und nach meinem Gusto umschreibt.
Hierzu legte ich unter /tmp/m6-geoip.py folgendes Python-Script ab:
import json
def response(context, flow):
f = open('/tmp/mitm.log','a+')
url = flow.request.get_url()
f.write('URL "' + url + '"' + "\n")
if url.endswith('geoInfo') or url.endswith('geoInfos'):
f.write(' matched' + "\n")
data = json.loads(flow.response.content)
# {"offset":"2","isp":"Andreas Fink","areas":[10],"country_code":"CH","asn":"AS6775","ip":"85.195.0.0"}
# {"offset":"2","isp":"QSC AG","areas":[1,2,3,10,11],"country_code":"FR","asn":"AS20676","ip":"92.222.83.58"} via http://www.franceproxy.net
#data["country_code"] = "FR"
#jsonOut = json.dumps(data)
jsonOut = '{"offset":"2","isp":"QSC AG","areas":[1,2,3,10,11],"country_code":"FR","asn":"AS20676","ip":"92.222.83.58"}'
flow.response.content = jsonOut
f.write(" " + jsonOut + "\n")
f.close()
Tipp 1: Da selten Leute vom Himmel gefallen sind, welche ein Script auf Anhieb richtig hingekriegt haben, hilft es zum Debugging, statt mitmproxy mitmdump zu verwenden:
# mitmdump -e -p 8888 -s "/tmp/m6-geoip.py"
Bei Python-Problemen mit dem Inline-Script wird der Stack Trace und die Fehlermeldung direkt auf der Kommandozeile ausgegeben.
Tipp 2: Die Ausgabe aller URLs in eine Log-Datei resultiert in Performance-Einbussen, kann für das Debugging aber sehr nützlich sein.
Anschliessend startete ich den mitmproxy neu:
# mitmproxy -p 8888 -s "/tmp/m6-geoip.py"
JSON-Quelle
Doch von wo hatte ich den JSON-String?
Nach etwas Googeln fand ich folgenden Proxy-Service:
Gibt man dort eine der obigen URLs ein, erhält man als Antwort den JSON-Code, welchen ich dann auch für die Umgehung des Geoblockers verwendete.
Kostenloser Tipp an die Web-Entwickler von M6: Die Geo-Location eines Aufrufs prüft man nicht im JavaScript auf dem Client, sondern auf dem Server.
Der erneute Versuch im Web-Browser
Ich lud die Web-Seite auf dem iPad erneut — erhielt zwar eine Fehlermeldung, dass trotzdem irgendetwas schief gelaufen war, doch im mitmproxy-Log fand sich die sehnlichst gesuchte URL zur m3u8-Datei:
Daraus — und mit Informationen der aktuellsten Sendung, welche sich auch für Schweizer streamen lässt — leitete ich die tatsächliche URL zur Master-Playlist ab:
Von dieser Datei war es dann nur noch ein Katzensprung zur m3u8-Datei mit dem Stream mit der höchsten Bit-Rate:
Und so lud ich den Stream dann mit ffmpeg herunter:
$ ffmpeg -protocol_whitelist file,http,https,tcp,tls -i "http://e112.cdn.m6web.fr/usp/mb_sd3/2/8/1/Le-1945_c11636016_19-45-du-dimanche-11/Le-1945_c11636016_19-45-du-dimanche-11_unpnp.ism/Le-1945_c11636016_19-45-du-dimanche-11_unpnp-audio_fra=93468-video_eng=1501000.m3u8" video.mp4

{kind=link}