Sonntag, 19. September 2021
Gestern lüpfte ich einen zweiten OpenVPN-Server von Debian Stretch auf Bullseye.
Das erfolgte leider nicht kurz- und schmerzlos. Ich kämpfte mit und debuggte während 16 Stunden (abzüglich 7 Stunden Schlaf) an folgenden Problemen:
Konsolen-, SSH- und Telnet-Logins dauern 1min30sec
D.h. nach Eingabe des Passwortes scheint das System zu hängen. Wer sich in Geduld übt, landet nach eineinhalb Minuten in der gewohnten Shell.
Bei mir bildeten sich in diesen ersten 90 Sekunden bereits viele Schweissperlen, denn wie flickt man ein Debian GNU/Linux, wenn man sich nicht mehr einloggen kann? Mittels grub in den Single User/Recovery Mode zu booten wäre ein noch grösserer Alptraum geworden …
Meldungen in syslog:
...
Sep 18 22:40:43 OPENVPN2 systemd[1]: Starting User Manager for UID 1000...
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Main process exited, code=exited, status=1/FAILURE
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Killing process 89451 (gpgconf) with signal SIGKILL.
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Killing process 89452 (awk) with signal SIGKILL.
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Killing process 89457 (dirmngr) with signal SIGKILL.
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Killing process 89452 (awk) with signal SIGKILL.
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Killing process 89457 (dirmngr) with signal SIGKILL.
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Failed with result 'exit-code'.
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Unit process 89452 (awk) remains running after unit stopped.
Sep 18 22:42:13 OPENVPN2 systemd[1]: user@1000.service: Unit process 89457 (dirmngr) remains running after unit stopped.
Sep 18 22:42:13 OPENVPN17 systemd[1]: Failed to start User Manager for UID 1000.
...
Die Lösung:
# apt-get remove gpgconf
...
The following packages will be REMOVED:
dirmngr duplicity gnupg gnupg-agent gnupg2 gpg gpg-agent gpg-wks-client gpg-wks-server gpgconf gpgsm libgmime-2.6-0 libgpgme11
libnotmuch4 mutt python3-gpg samba-dsdb-modules scdaemon
Die vielen zu deinstallierenden Pakete liessen mich kurz zweifeln, aber das System lief nach deren Deinstallation problemlos weiter.
Quelle: WireGuard Bounce Server Setup
Wobei, wenn ich die Kommentare so lese: Eventuell war gpgconf gar nicht das Problem, sondern der Nameserver, der nicht reagierte (siehe unten).
Netzwerkprobleme
Probleme mit named und localhost
BIND 9 ist zwar an localhost (127.0.0.1) gebunden und lauscht auf dem Interface …
# lsof -i :53
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
named 653 bind 23u IPv4 15673 0t0 UDP localhost:domain
named 653 bind 24u IPv4 15679 0t0 UDP localhost:domain
named 653 bind 25u IPv4 15680 0t0 TCP localhost:domain (LISTEN)
named 653 bind 27u IPv4 15681 0t0 TCP localhost:domain (LISTEN)
named 653 bind 29u IPv4 15682 0t0 UDP 10.1.2.3:domain
named 653 bind 30u IPv4 15683 0t0 UDP 10.1.2.3:domain
named 653 bind 31u IPv4 15684 0t0 TCP 10.1.2.3:domain (LISTEN)
named 653 bind 32u IPv4 15685 0t0 TCP 10.1.2.3:domain (LISTEN)
… aber die Namensauflösung funktioniert nicht. Wenn man mit telnet 127.0.0.1 53 eine Session aufbauen will, hängt die Verbindung.
Mittels strace analysierte ich dann was im Hintergrund genau vor sich ging, und verglich die Ausgabe mit einem strace auf einem Server, bei dem die Namensauflösung funktionierte:
Defekter Server:
# strace ping -c 1 emeidi.com
...
socket(AF_INET, SOCK_DGRAM|SOCK_CLOEXEC|SOCK_NONBLOCK, IPPROTO_IP) = 5
setsockopt(5, SOL_IP, IP_RECVERR, [1], 4) = 0
connect(5, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("127.0.0.1")}, 16) = 0
clock_gettime(CLOCK_REALTIME, {tv_sec=1631995746, tv_nsec=794103764}) = 0
poll([{fd=5, events=POLLOUT}], 1, 0) = 1 ([{fd=5, revents=POLLOUT}])
sendto(5, "{\311\1\0\0\1\0\0\0\0\0\0\6emeidi\3com\0\0\1\0\1", 28, MSG_NOSIGNAL, NULL, 0) = 28
poll([{fd=5, events=POLLIN}], 1, 1000) = 0 (Timeout)
clock_gettime(CLOCK_REALTIME, {tv_sec=1631995747, tv_nsec=795739261}) = 0
poll([{fd=5, events=POLLOUT}], 1, 0) = 1 ([{fd=5, revents=POLLOUT}])
sendto(5, "{\311\1\0\0\1\0\0\0\0\0\0\6emeidi\3com\0\0\1\0\1", 28, MSG_NOSIGNAL, NULL, 0) = 28
poll([{fd=5, events=POLLIN}], 1, 1000) = 0 (Timeout)
close(5) = 0
...
Funktionierender Server:
# strace ping -c 1 emeidi.com
...
socket(AF_INET, SOCK_DGRAM|SOCK_CLOEXEC|SOCK_NONBLOCK, IPPROTO_IP) = 5
setsockopt(5, SOL_IP, IP_RECVERR, [1], 4) = 0
connect(5, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("127.0.0.1")}, 16) = 0
poll([{fd=5, events=POLLOUT}], 1, 0) = 1 ([{fd=5, revents=POLLOUT}])
sendto(5, "UK\1\0\0\1\0\0\0\0\0\0\6emeidi\3com\0\0\1\0\1", 28, MSG_NOSIGNAL, NULL, 0) = 28
poll([{fd=5, events=POLLIN}], 1, 1000) = 1 ([{fd=5, revents=POLLIN}])
ioctl(5, FIONREAD, [463]) = 0
recvfrom(5, "UK\201\200\0\1\0\1\0\r\0\r\6emeidi\3com\0\0\1\0\1\300\f\0\1"..., 2048, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("127.0.0.1")}, [28->16]) = 463
poll([{fd=5, events=POLLOUT}], 1, 999) = 1 ([{fd=5, revents=POLLOUT}])
sendto(5, "W}\1\0\0\1\0\0\0\0\0\0\6emeidi\3com\0\0\34\0\1", 28, MSG_NOSIGNAL, NULL, 0) = 28
poll([{fd=5, events=POLLIN}], 1, 998) = 1 ([{fd=5, revents=POLLIN}])
ioctl(5, FIONREAD, [278]) = 0
recvfrom(5, "W}\201\200\0\1\0\0\0\0\0\r\6emeidi\3com\0\0\34\0\1\1a\fr"..., 65536, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("127.0.0.1")}, [28->16]) = 278
close(5) = 0
...
Macht man dasselbe mit der internen IP des Servers (bspw. 10.1.2.3) kann eine Session aufgebaut werden. Die Namensauflösung konnte ich nicht durchführen, weil mir der oder die Befehle nicht geläufig waren — im Nachhinein aber las ich dann, dass es sich bei DNS-Abfragen nicht um Klartextkommandos handelt.
Nun gut, dies bewog mich zu einem Workaround, ohne das eigentliche Problem zu beseitigen. Ich passte kurzerhand meine /etc/resolv.conf an:
#nameserver 127.0.0.1
nameserver 10.1.2.3
options timeout:1
options single-request
Ich vermutete zuerst Probleme in systemd-resolved. Installieren resp. entfernen tut man das Paket mit:
# apt-get install libnss-resolve
# apt-get remove libnss-resolve
Ist das Paket installiert, hat man neben /etc/resolv.conf auch noch Konfigurationen in /etc/systemd/resolved.conf und /run/systemd/resolve/resolve.conf. Typischer systemd-Wahnsinn. (siehe dazu Ubuntu – 18.04 Unable to connect to server due to “Temporary failure in name resolution” sowie Ubuntu 18.04 DNS resolution fails after a while)
Als ich systemd-resolved mit meinen Pröbelein zerschossen hatte, tauchten in /var/log/syslog noch folgende Fehlermeldungen auf:
Sep 18 20:35:04 localhost dbus-daemon[329]: [system] Activating via systemd: service name='org.freedesktop.resolve1' unit='dbus-org.freedesktop.resolve1.service' requested by ':1.15' (uid=0 pid=2015 comm="resolvectl ")
Sep 18 20:35:04 localhost dbus-daemon[329]: [system] Activation via systemd failed for unit 'dbus-org.freedesktop.resolve1.service': Unit dbus-org.freedesktop.resolve1.service not found.
Siehe auch Activation via systemd failed for unit ‚dbus-org.freedesktop.resolve1.service‘: Unit dbus-org.freedesktop.resolve1.service not found
Site-to-site OpenVPN erlaubt Pings in nur eine Richtung
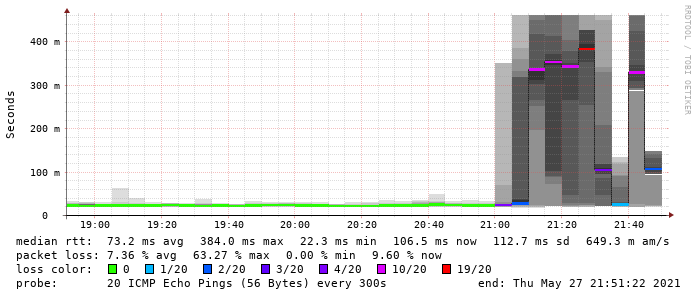
Die Sache wurde immer mysteriöser: Aus dem entfernten Subnetz, in welchem der hier Probleme verursachende Server steht, konnte ich problemlos zur anderen Site pingen. Sowohl den VPN-Endpunkt, als auch alle anderen IPs im Subnetz hier. Das funktionierte auch von anderen Geräten im entfernten Subnetz aus.
Doch im Umkehrschluss funktionierte das nicht; d.h. von meinem Heimnetzwerk konnte ich nur den OpenVPN-Endpunkt pingen, aber nichts im entfernten Subnetz. Die ICMP-Pakete kamen zwar beim Zielgerät an (bspw. dem Internet-Router), dieser antwortete, aber das Antwortpaket wurde dann von auf dem entfernten OpenVPN-Endpunkt nicht von eth0 auf tun0 weitergeleitet.
Immerhin lernte ich für das Debugging nützliche tcpdump-Befehle kennen:
# tcpdump -n icmp and host 10.1.2.1
# tcpdump -i tun0 -n icmp and host 10.1.2.1
# tcpdump -i eth0 -n icmp and host 10.1.2.1
Die Ausgabe ist auch deshalb hilfreich, weil derselbe ping-Prozess immer dieselbe id trägt. Und die Sequenznummern sieht man auch gleich angezeigt. So konnte man isolieren, wo genau die ICMP-Pakete „verloren“ gingen respektive noch durchkamen.
Ausserdem kann man iptables so konfigurieren, dass sie verarbeitete Pakete ins syslog loggen (eine Regel iptables -I FORWARD -i eth0 -o tun0 -j ACCEPT existiert dabei schon und ist aktiv):
# iptables -I FORWARD -i eth0 -o tun0 -j LOG --log-prefix "OUTGOING "
# iptables -I FORWARD -i tun0 -o eth0 -j LOG --log-prefix "INCOMING "
Das Logging wird deaktiviert, indem man die Regel wieder entfernt:
# iptables -D FORWARD -i eth0 -o tun0 -j LOG --log-prefix "OUTGOING "
# iptables -D FORWARD -i tun17 -o eth0 -j LOG --log-prefix "INCOMING "
In dmesg entdeckte ich dann auch noch folgende Fehlermeldungen, was mich bewog, den Kernel zu aktualisieren:
...
cgroup2: unknown option "nsdelegate,memory_recursiveprot"
...
Die finale Lösung: Aktualisiere von Kernel-Version 4.9.0-16 auf 5.10.46-4, und Neustart.
# apt-get install linux-image-amd64