Mittwoch, 29. Juni 2016
Vor einigen Monaten wurde ich durch die Ankündigung einer Preiserhöhung beim schwedischen Pingdom aufgeschreckt und sah mich deshalb etwas genauer auf dem Markt für Web-Site-Monitoring herum.
Fündig wurde ich beim us-amerikanischen StatusCake, welches kostenloses Monitoring einer unlimitierten Zahl an Web-Sites bietet — sofern man damit leben kann, das Checks nur alle fünf Minuten erfolgen. Im Nu hatte ich um die 50 Tests eingerichtet — von SSH, OpenVPN, PPTP über ordinäres HTTP/S bis hin zu Dashboards, welche Laufzeitdaten zusammenziehen und mich mittels von 200 abweichenden HTTP-Codes bei Problemen warnen.
Das Monitoring funktionierte wunderprächtig, bis Hostpoint letzte Woche damit begann, von Apache 2.2 auf Apache 2.4 zu migrieren:
Apache Update
21.06.2016, 00:00 Uhr – 31.07.2016, 00:00 Uhr
Wir aktualisieren derzeit auf sämtlichen Server die Apache Version von 2.2 auf 2.4. Dieses Update ist grösstenteils transparent, nur in den unten aufgeführten Szenarien muss eine Anpassung vorgenommen werden. Für das Update wird es eine Unterbrechung von wenigen Sekunden geben.
HTTP/2
Neu Unterstützen wir mit Apache 2.4 das Protokoll HTTP/2. Dieses steigert die Effizienz bei der Kommunikation zwischen Browser und Server: Mehr Durchsatz, mehr Parallelität, weniger Latenz. Vor allem moderne web-2.0-typische Webseiten mit vielen kleinen Resourcen profitieren davon. Voraussetzung für HTTP/2 ist eine TLS geschützte Verbindung (SSL Zertifikat). Dieses steht dank FreeSSL all unseren Kunden zur Verfügung.
…
Quelle: Hostpoint – Statusseite
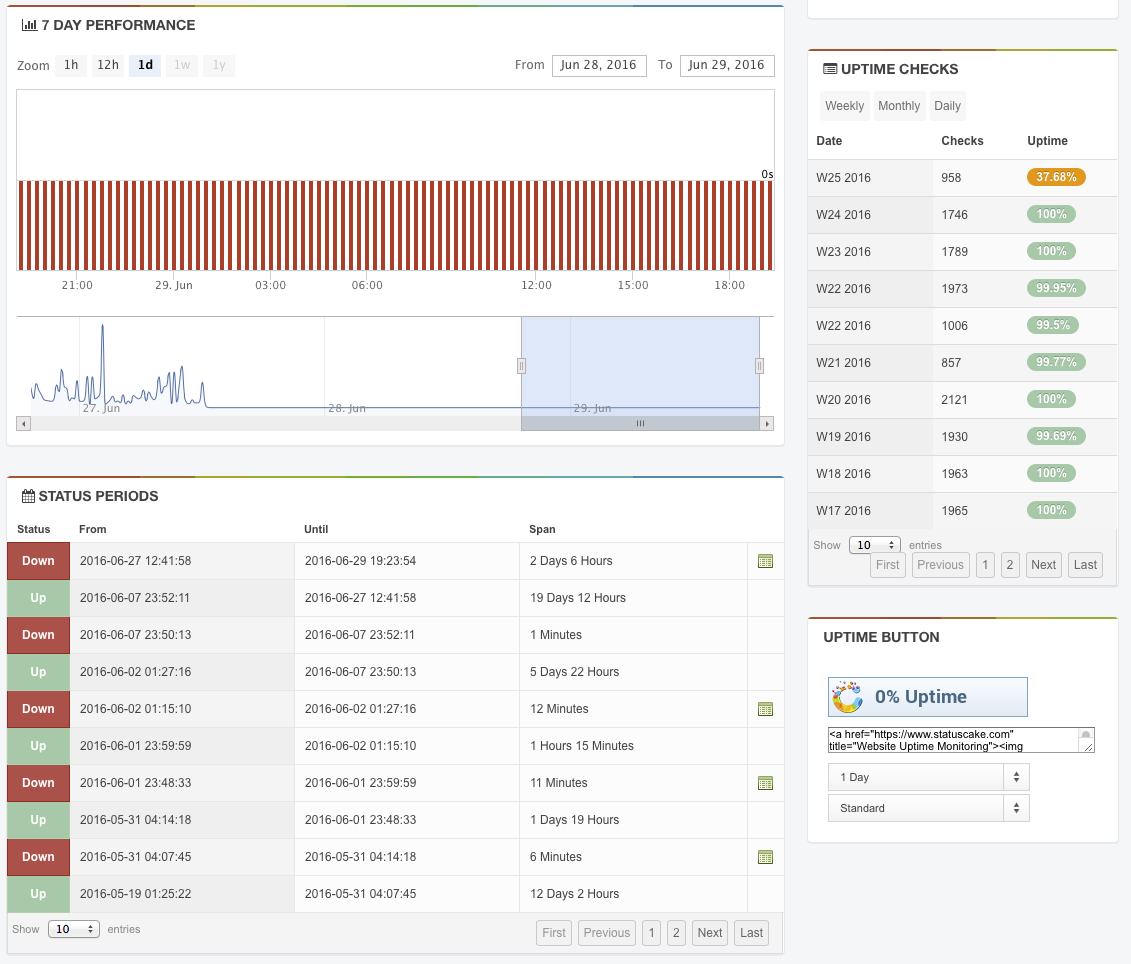
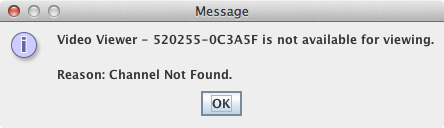
Wahrscheinlich seit der Migration auf die neue Web-Server-Version meldete StatusCake für jede meiner bei Hostpoint gehosteten Web-Sites Folgendes:
Die konkreten Ausfallzeiten sind:
- bibliothek-neuenegg.ch
- 2016-06-21 13:02:54 (Server: sl51.web.hostpoint.ch / s20)
- sek-neuenegg.ch
- 2016-06-21 13:09:48 (Server: sl58.web.hostpoint.ch / s27)
- geschichtstage.ch
- 2016-06-27 12:41:58 (Server: sl103.web.hostpoint.ch / s36)
- ahc-ch.ch
- 2016-06-27 12:44:38 (Server: sl103.web.hostpoint.ch / s36)
Erste Anlaufstelle: Hostpoint
Zuerst dachte ich mir: Klarer Fall, da hat Hostpoint geschludert.
Ich kontaktierte dementsprechend deren Support am 28. Juni um 14:51 Uhr, um 17:22 Uhr erhielt ich die fachkundige Antwort von Jonas. Mittels eines Auszugs aus dem Domain Log legte er mir glaubwürdig dar, dass die StatusCake Probes den Server der Bibliothek Neuenegg bis heute alle fünf Minuten anpingen:
...
107.170.219.46 - - [28/Jun/2016:16:45:57 +0200] "GET / HTTP/1.1" 200 8770 "-" "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/98 Safari/537.4 (StatusCake)"
107.170.227.23 - - [28/Jun/2016:16:51:00 +0200] "GET / HTTP/1.1" 200 8770 "-" "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/98 Safari/537.4 (StatusCake)"
217.148.43.202 - - [28/Jun/2016:16:56:00 +0200] "GET / HTTP/1.1" 200 8770 "-" "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/98 Safari/537.4 (StatusCake)"
37.235.48.42 - - [28/Jun/2016:17:01:29 +0200] "GET / HTTP/1.1" 200 8770 "-" "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/98 Safari/537.4 (StatusCake)"
46.101.110.32 - - [28/Jun/2016:17:06:37 +0200] "GET / HTTP/1.1" 200 8770 "-" "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/98 Safari/537.4 (StatusCake)"
...
Eine manuelle Kontrolle meinerseits zeigte, dass dies auch bei allen anderen oben genannten Servern der Fall war.
Der Web-Server antwortet auf die HTTP/1.1-Anfrage mittels des HTTP-Codes 200 und liefert 8770 Bytes an Daten zurück. Ein kurzer Test mit wget von soeben zeigt, dass das durchaus hinkommt (wget erhält „nur“ 8697 Bytes zurück, also ca. 100 Bytes weniger — dies auf Grund einer Anpassung im Inhalt der Homepage; sprich: vernachlässigbar):
$ wget bibliothek-neuenegg.ch
--2016-06-29 19:34:30-- http://bibliothek-neuenegg.ch/
Auflösen des Hostnamens »bibliothek-neuenegg.ch (bibliothek-neuenegg.ch)« … 217.26.52.30
Verbindungsaufbau zu bibliothek-neuenegg.ch (bibliothek-neuenegg.ch)|217.26.52.30|:80 … verbunden.
HTTP-Anforderung gesendet, auf Antwort wird gewartet … 301 Moved Permanently
Platz: https://bibliothek-neuenegg.ch/ [folgend]
--2016-06-29 19:34:31-- https://bibliothek-neuenegg.ch/
Verbindungsaufbau zu bibliothek-neuenegg.ch (bibliothek-neuenegg.ch)|217.26.52.30|:443 … verbunden.
HTTP-Anforderung gesendet, auf Antwort wird gewartet … 200 OK
Länge: nicht spezifiziert [text/html]
Wird in »»index.html«« gespeichert.
index.html [ <=> ] 8,49K --.-KB/s in 0s
2016-06-29 19:34:31 (49,4 MB/s) - »index.html« gespeichert [8697]
Zweite Anlaufstelle: StatusCake
Nun gut. Dementsprechend stellte ich alle wichtigen Infos zusammen, die einem Second-Level-Supporter nützlich erscheinen könnten und kontaktierte am selben Tag um 19:09 Uhr Schweizer Zeit den Support von StatusCake. Dan antwortete mir am folgenden Tag um 11:07 Uhr morgens, ging aber wie von us-amerikanischem Support-Personal gewohnt überhaupt nicht auf mein Anliegen ein. Stattdessen erhielt ich wohl einen Knowledge-Base-Artikel als Standardantwort:
We use a large global network of testing servers, it’s looking to me like you may need to whitelist our IPs on these servers, you can grab our full lists here – https://www.statuscake.com/kb/knowledge-base/what-are-your-ips/
9 Minuten später hatte ich ihm bereits geantwortet (wenn man einen Supporter schon mal „dran“ hat, sollte man ihn nicht mehr gehen lassen): Ich wies ihn darauf hin, dass die Apache Access Logs zeigen, dass die Server alle fünf Minuten Besuch von der Probe bekämen, Whitelisting also definitiv nicht das Problem sei.
Um 15:43 Uhr schrieb mir Dan zurück:
Had a look into this one. The only thing I can see that might be causing this is the introduction of HTTP/2, we don’t currently support this and will be giving a down result for any HTTP/2-only enabled sites.
Immerhin schien er die Status-Seite von Hostpoint aufgerufen und dort gelesen zu haben, dass HTTP/2 eingeführt wurde. Das wäre durchaus ein Ansatz, doch wieso taucht die Probe dann mit HTTP/1.1 in den Logs auf? Ich habe Dan zurückgeschrieben, doch bis jetzt ist noch keine weiterführende Antwort eingetrudelt. Ich bleibe dran!
Test mit wget
In der Zwischenzeit kam mir nun auch noch die Idee, dass der Web-Server vielleicht auf Grund des StatusCake User-Agents plötzlich meint, dass die Gegenseite fähig ist, HTTP/2 zu sprechen — und die Verbindung auf HTTP/2 upgradet.
Mit meinem lokal installierten wget probierte ich es aus:
$ wget --server-response --user-agent="Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/98 Safari/537.4 (StatusCake)" https://www.bibliothek-neuenegg.ch/
--2016-06-29 19:47:56-- https://www.bibliothek-neuenegg.ch/
Auflösen des Hostnamens »www.bibliothek-neuenegg.ch (www.bibliothek-neuenegg.ch)« … 217.26.52.30
Verbindungsaufbau zu www.bibliothek-neuenegg.ch (www.bibliothek-neuenegg.ch)|217.26.52.30|:443 … verbunden.
HTTP-Anforderung gesendet, auf Antwort wird gewartet …
HTTP/1.1 200 OK
Date: Wed, 29 Jun 2016 17:47:56 GMT
Server: Apache/2.4
X-Powered-By: PHP/7.0.7
Set-Cookie: PHPSESSID=dbneu9nses8n52ge8i4esj72b1; path=/
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate
Pragma: no-cache
Upgrade: h2,h2c
Connection: Upgrade, Keep-Alive
X-Frame-Options: SAMEORIGIN
X-Content-Type-Options: nosniff
Keep-Alive: timeout=5, max=100
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
Länge: nicht spezifiziert [text/html]
Wird in »»index.html«« gespeichert.
index.html [ <=> ] 8,49K --.-KB/s in 0s
2016-06-29 19:47:56 (30,9 MB/s) - »index.html« gespeichert [8697]
Wie man sieht antwortet der Hostpoint-Server brav mit HTTP/1.1 200 OK (wget spricht KEIN HTTP/2; hätte der Server also — nicht-standardkonform notabene — mit HTTP/2 geantwortet, hätte wget mir einen Fehler angezeigt.).
Dritte Reaktion: Hostpoint entdeckt Blog-Post
Heute (1. Juli 2016) trudelte kurz nach 11 Uhr morgens eine neue Nachricht zu meinem eigentlich als geschlossen geglaubten Support-Ticket bei Hostpoint ein: Jessica nahm Bezug auf meinen kürzlich veröffentlichten Blog-Artikel und teilte mir mit, dass die Angelegenheit intern noch einmal genauer angeschaut worden war. Sie war es, welche mir in diesem E-Mail den entscheidenden Hinweis gab:
StatusCake scheint NodeJS zu verwenden. Dieses hat einen Bug, wenn Apache einen Upgrade Header mitschickt. Dies ist HTTP-Konform und ist so korrekt.
Sie können die Details in folgendem Threads nachlesen:
NodeJS unable to make https requests when h2 enabled in Apache 2.4.18 #73
http: do not emit `upgrade` on advertisement #4337
Hostpoint hatte mit ein wenig Recherche herausgefunden, dass ältere Versionen von NodeJS HTTP/HTTPS-Verbindungen zu Web-Servern abbrechen, wenn dieser mit einer HTTP/2-Upgrade-Anforderung antwortet. Und irgendwie hatte Hostpoint weiter bemerkt, dass StatusCake höchstwahrscheinlich NodeJS für die Abfragen einsetzt.
Klasse, genau solches Debugging liebe ich an meinem Beruf so sehr — und umso mehr freut es mich, wenn sich Dienstleister in einen Bug verbeissen und alles tun möchten, um diesen zu beheben.
Ich bedankte mich bei Jessica und wendete mich anschliessend gleich Dan von StatusCake zu.
Vierte Reaktion: StatusCake
Da ich von Dan seit meiner Rückmeldung nichts mehr gehört hatte, antwortete ich erneut auf sein letztes Mail und beschrieb ihm auf Englisch die von Hostpoint vermutete Ursache hinter dem Problem. Ich hatte ehrlich gesagt nicht viel Hoffnung, dass ich jemals wieder von StatusCake hören würde (Kunde, der (noch) keinen Umsatz generiert, und mit komischen Problemen nervt) — doch ich täuschte mich auch hier.
Um 11:35 Uhr ging meine Anfrage an Dan raus, um 11:44 Uhr (innert 9 Minuten!) lag bereits seine Antwort in der INBOX. Und dieses Mal nichts aus der Büchse, sondern eine tatsächlich auf meine Anfrage Bezug nehmende Antwort.
Dies wahrscheinlich aus verschiedenen Gründen:
- Ich teilte ihm mit, dass Hostpoint der grösste Hoster in der Schweiz sei
- Ich erwähnte NodeJS
- Ich erwähnte die Nachricht von Jessica von Hostpoint und fügte die Links auf die NodeJS-Bugs ein
- Ich erwähnte, dass auf Grund der weltweit laufenden Upgrades auf Apache 2.4 dieses Problem exponentiell zunehmen würde
Dan schrieb mir:
[…] this has been escalated to our engineers. We are working on this and we will have it sorted asap, it’s a big job so you’ll appreciate that the resolution will not be instant. Sorry if I wasn’t great at troubleshooting this at first – the results we were seeing did not make sense.
Dann warten wir also geduldig, bis StatusCake ihre NodeJS-Installation upgegradet hat …